DeepSeek-R1 and the Future of Generative AI: A Comprehensive Breakdown
Your Complete Guide to DeepSeek-R1: Core Concepts, Research Insights, and Everything in Between



Table of contents
- Introduction
- I. Foundational Concepts
- II. DeepSeek-R1: A Section-by-Section Breakdown
- Introduction
- DeepSeek-R1-Zero: Pure Reinforcement Learning
- Training Without a Safety Net
- The GRPO Algorithm: Learning by Trial and Error (But Efficiently)
- Rule-Based Rewards: Clear Incentives for the Model
- Why use a rule-based system?
- Simple Training Template
- Emergent Behaviours: The Model Learns to Think
- Performance Results: Competing with Top Models
- Limitations of DeepSeek-R1-Zero: The Need for Refinement
- DeepSeek-R1: A Multi-Stage Approach to Refinement
- "Cold Start": A Guiding Hand Before Reinforcement Learning
- Benefits of Cold Start Data
- Reasoning-Oriented Reinforcement Learning
- Rejection Sampling and Supervised Fine-Tuning (SFT)
- Final Reinforcement Learning for All Scenarios
- Distillation: Transferring Reasoning to Smaller Models
- Impressive Performance of Distilled Models
- Discussion: Key Findings and Insights
- The End
Introduction
If you’re even remotely interested in AI - and let’s face it, who isn’t these days - you’ve probably seen the name DeepSeek-R1 popping up all over your LinkedIn feed. In the field of AI, new developments emerge literally every day, so what makes DeepSeek-R1 stand out? What’s so special about it? That’s exactly what this blog is here to explore - deeply and thoroughly.
But before diving into the details, let me give you the short answer to the aforementioned questions: DeepSeek-R1 is an open-source large language model developed in China that rivals OpenAI’s GPT-1o and GPT-1o-mini in performance. What’s even more impressive is that it achieved this level of sophistication while being trained on far fewer GPUs than other large language models. People are excited because this could be a potential game-changer in generative AI.
Not only has DeepSeek-R1 demonstrated that state-of-the-art language models can be trained with significantly less computational power, but its open-source nature is also sparking widespread excitement and appreciation. For the first time, researchers have full access to a cutting-edge language model’s training methodology, weights, and architecture, allowing them to build upon and improve it further. Until now, such state-of-the-art models have been strictly closed-source. DeepSeek-R1 is changing the game, offering unprecedented opportunities for collaboration and innovation in AI.
My aim in writing this blog post is to give readers, whether beginners or AI-experts, a solid understanding of DeepSeek-R1’s training based on its research paper. I’ll break down concepts in a way to make you get a good understanding of them, without going too deep into the technical details. We’ll first start with some foundational concepts you should know, and then move on to break down the DeepSeek-R1 paper, section by section. Hopefully, by the time you’re done reading, you’ll have a strong understanding of the research paper and be able to appreciate fully why DeepSeek-R1 is making waves and what’s so groundbreaking about it.
The blog consists of two parts; first, we’ll explore the core concepts powering DeepSeek-R1’s training and get familiarised with them. Then in the second part, we’ll go through a detailed breakdown of the DeepSeek-R1 research paper and see how the aforementioned concepts have been applied.
I. Foundational Concepts
The DeepSeek-R1 paper mentions several training methods, conventions and terminologies. To actually understand what it’s referring to, there are a few LLM-related concepts you should be familiar with. Let's dive into them, starting from the basics and building from there.
How Language Models Work
The Guessing Game
Do you remember the time when you first used ChatGPT at the close of the year 2022? That “mind-blown” feeling that you must have gotten at the responses generated - it was really the start of an era. And how far LLMs have come since then! Well, at the time obviously it seemed like some kind of magic, but the truth is that the way LLMs work is not magic, but the result of very intricate, self-evolving algorithms.
To simplify it as much as possible, think of a language model as a clever word guessing machine. It's a type of generative model, which means it's designed to create things, in this case, text. The main thing it does is try to predict the next word (or part of a word, called a 'token') in a sequence.
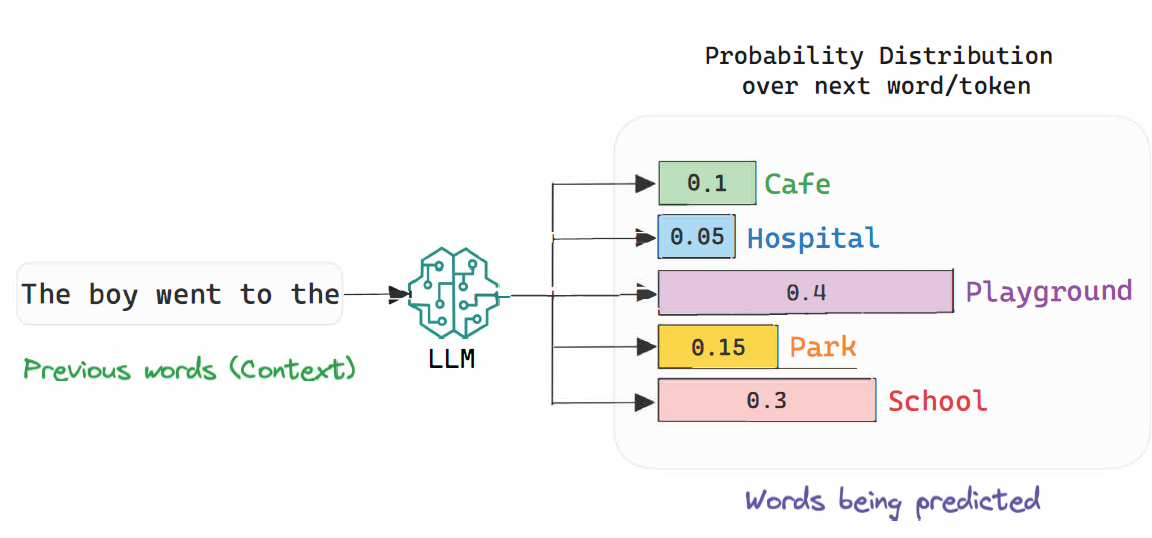
The main thing an LLM does is try to predict the next word in a sequence
Predicting the Next Word: Imagine you're reading a sentence like, "The cat sat on the..." A language model is like someone trying to guess what the next word will be. It might guess "mat," "sofa," or "chair." It does this by looking at all the words before it and figuring out which word is most likely to come next.
It doesn't just pick one word, but it actually creates a list of probabilities of all the words it knows, so the word it thinks is most likely gets a higher probability score than the others. Then, based on this probability score, it chooses a word, and then puts that word back in the sentence and guesses again. It keeps doing this over and over, building up a complete sentence or response.

The LLM chooses a word, and then puts that word back in the sentence and guesses again
How does it get so good at guessing words?
These language models learn by reading huge amounts of text data. Think of all the books, articles, websites, and code on the internet. The language model reads through all of this, learning the patterns of language, just like how children learn to speak by hearing others speak.
By looking at all this text, it figures out which words usually go together, what kinds of sentences make sense, and how to write in different styles and about different topics.
So, in short, language models are prediction machines that learn to guess the next word in a sequence by reading vast amounts of text. They can use this ability to create new text, answer questions, or even write code.
Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning (SFT) is a crucial technique in training Large Language Models (LLMs), designed to refine a model's performance on specific tasks. Think of it like this: if you're teaching someone a new skill, you wouldn't just give them the rules; you'd show them examples of how to do it correctly, and then have them practice. SFT does something similar for language models.
The Basics
In SFT, a language model is trained using a dataset that contains pairs of inputs and their desired outputs. These input-output pairs act as examples of how the model should respond in specific situations.
The model's goal during SFT is to learn the relationships between these inputs and outputs, so it can generate appropriate responses when faced with similar inputs in the future.
How It Works
The language model is fed a prompt (the input) and is asked to generate a response. The model's generated response is then compared to the ideal output that is included in the dataset. If the generated response doesn't match the ideal output, the model's internal settings (its "parameters") are adjusted so that its future responses are more likely to match the desired output.
This process is repeated many times, using many different examples from the training data. Over time, the model learns to produce outputs that are very similar to those in the training dataset.
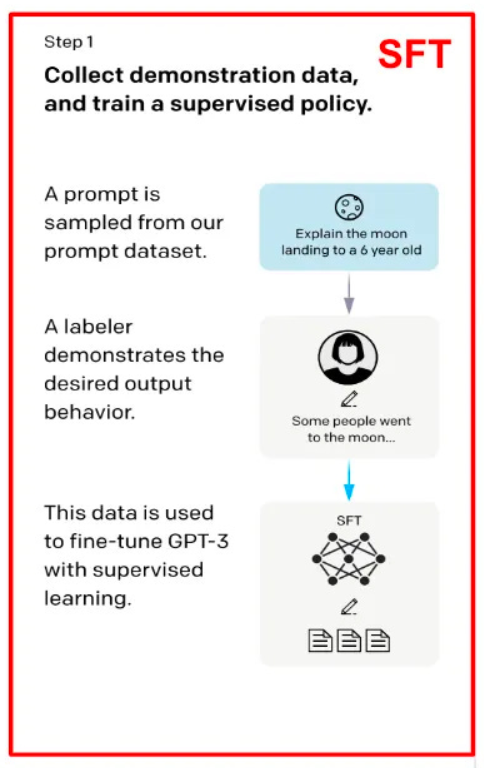
In SFT, a language model is trained using a dataset that contains pairs of inputs and their desired outputs
SFT in Practice
If you want a language model to be good at writing summaries, you would train it using SFT with a dataset of articles and their corresponding summaries.
To make a chatbot, you might use SFT to train a model to respond in a polite and helpful way by providing examples of conversations.
A language model can be trained using SFT to follow a specific format, such as always greeting the user and avoiding bad language.
Reinforcement Learning
Reinforcement Learning (RL) is a method for training a system, called an "agent", to make the best decisions in a particular situation, known as an "environment". The agent learns through trial and error, receiving feedback that tells it whether its actions were good or bad, so that it can adjust its behaviour accordingly. The goal of RL is to train the agent to make the decisions that will get it the most reward. The agent isn't directly told to do this, but it discovers this through trial and error, guided by the reward system.
Think about training a cat using treats. The cat is the agent and its actions, like sitting or jumping, are its policy – its way of choosing what to do. The house is the environment for the cat. You give the cat a treat (a reward) when it does something you want and maybe say "no" if it does something bad. Over time, the cat learns which actions get it treats, and it will repeat those actions.
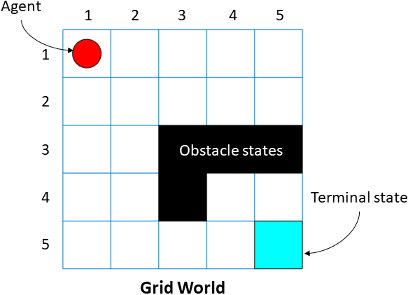
The goal of RL is to train the agent to make the decisions that will get it the most reward
Key components
Agent: This is the decision-maker. It could be anything from a robot, to a game-playing computer, or a language model.
Environment: This is the setting where the agent operates. This could be a game, a physical space, or in the case of DeepSeek-R1, it could be a set of problems to solve.
Policy: This is the agent's strategy for choosing actions. It is the method the agent uses to decide what to do in any given situation. For a language model, the policy is its method for generating the next word in a sentence.
Reward: This is the feedback the agent receives for its actions. It is like the treats you give the cat. A positive reward means the agent did something good, while a negative reward means it did something bad.
In short, RL is a way to train systems to make good decisions using feedback and experience (as compared to explicit instructions), much like how you would teach a cat a trick using treats.
SFT vs RL
SFT requires a curated dataset of input-output pairs to guide the training.
In contrast, RL does not rely on such a dataset. Instead, it uses a reward system to incentivize the language model to learn for itself. This allows the model to develop new reasoning strategies autonomously.
In short, SFT is like showing a student examples of the correct answers, while RL is like setting up a reward system so the student can discover the correct answers through trial and error. Although they are very different ways of teaching a language model, both are useful techniques in improving the abilities of LLMs.
PPO, DPO & GRPO
GRPO is a core concept mentioned in the DeepSeek-R1 Paper. To understand GRPO, we need to first touch upon its predecessors, PPO and DPO.
First, it's important to understand that GRPO (Group Relative Policy Optimization), PPO (Proximal Policy Optimization) and DPO (Direct Preference Optimization) are all reinforcement learning algorithms used to train language models. These algorithms help the models learn to generate text that aligns with a specific objective, such as solving reasoning tasks or following human preferences. The language model itself is the 'policy' which chooses the next token based on the current input. The goal is to train the model (the policy) to take actions (generate tokens) that maximise the 'reward'.
We have already explored RL in detail, let's move on to the other key areas.
PPO (Proximal Policy Optimization)
PPO is a popular RL algorithm that trains a policy by iteratively improving on its past performance.
It uses a value function to estimate the expected future reward for each state. This helps the model to understand the long-term consequences of its actions, but adds to the complexity of training.
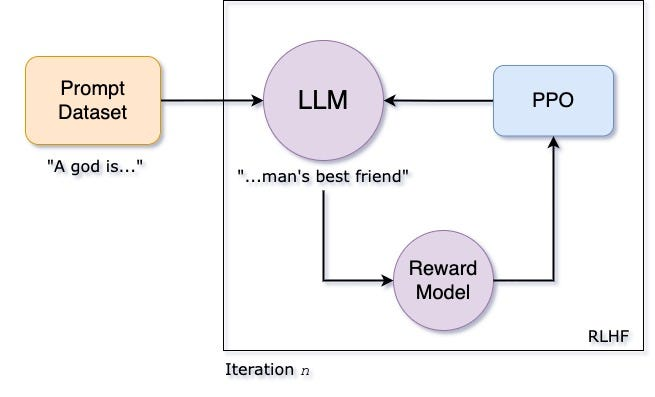
PPO trains a policy by iteratively improving on its past performance
PPO uses a method called 'clipping' to ensure that the policy does not change too drastically at each step, thus promoting a more stable training process.
PPO is an 'on-policy' algorithm which means that it needs to sample new data using the updated policy for each iteration. The data used to train the model is collected while the model is actively exploring, and the model uses that data immediately in its training. Each time the model is updated it needs new data, and this can be computationally expensive. In language models this means the model is trained with data it produced, and after each update, new responses must be generated.
DPO (Direct Preference Optimization)
DPO is a more recent RL algorithm that simplifies the training process by directly optimizing the policy based on human preferences.
Instead of training a separate reward model, it uses a dataset of ranked preferences for different outputs to directly update the policy.
This removes the need for a separate reward model, making training more stable and efficient.
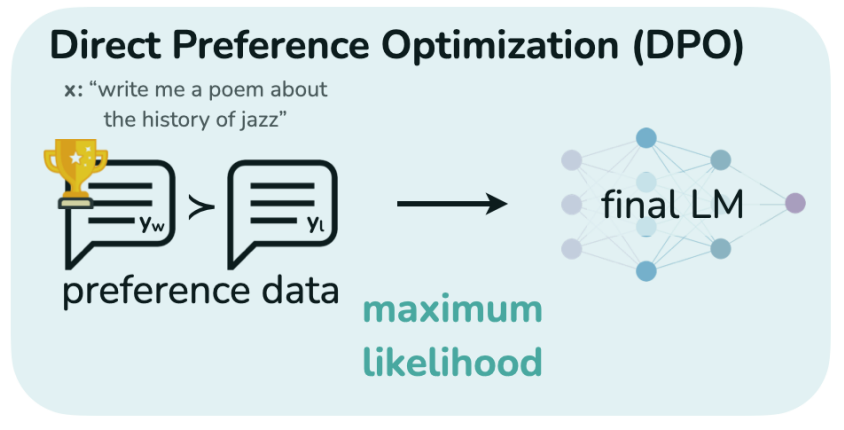
DPO simplifies the training process by directly optimizing the policy based on human preferences
DPO is an 'off-policy' algorithm which means that it can use previously sampled data during the training process. The data used to train the model is collected before the model is updated, and that data can be reused for training multiple times. This is very useful to save on compute (both cost and time) as generating outputs from large models can be expensive and time-consuming. In language models, this means that a model can train on a dataset of past responses, and these same responses can be reused in further training iterations, without requiring new responses to be generated.
GRPO (Group Relative Policy Optimization)
GRPO is similar to PPO but it forgoes the use of a separate, complex value function, saving training costs.
GRPO works by generating a group of different outputs for the same input prompt and then compares the rewards these outputs receive. For example, if a model is asked a question, it might generate several different answers. Instead of trying to calculate an absolute value for each answer (which is what a value function would do), GRPO assesses how each answer performed relative to the other answers generated for that same question. This means it looks at which answers got the best rewards within that specific group and uses this relative information to improve the model's policy.
This 'baseline' is simply the average reward of the outputs in the group, which allows the model to then calculate an advantage term. In effect, GRPO asks: "For this question, was this answer better or worse than the (average of the) other answers I gave?" rather than trying to figure out how good the answer was on an absolute scale, making it more computationally efficient than methods that use a separate value function.
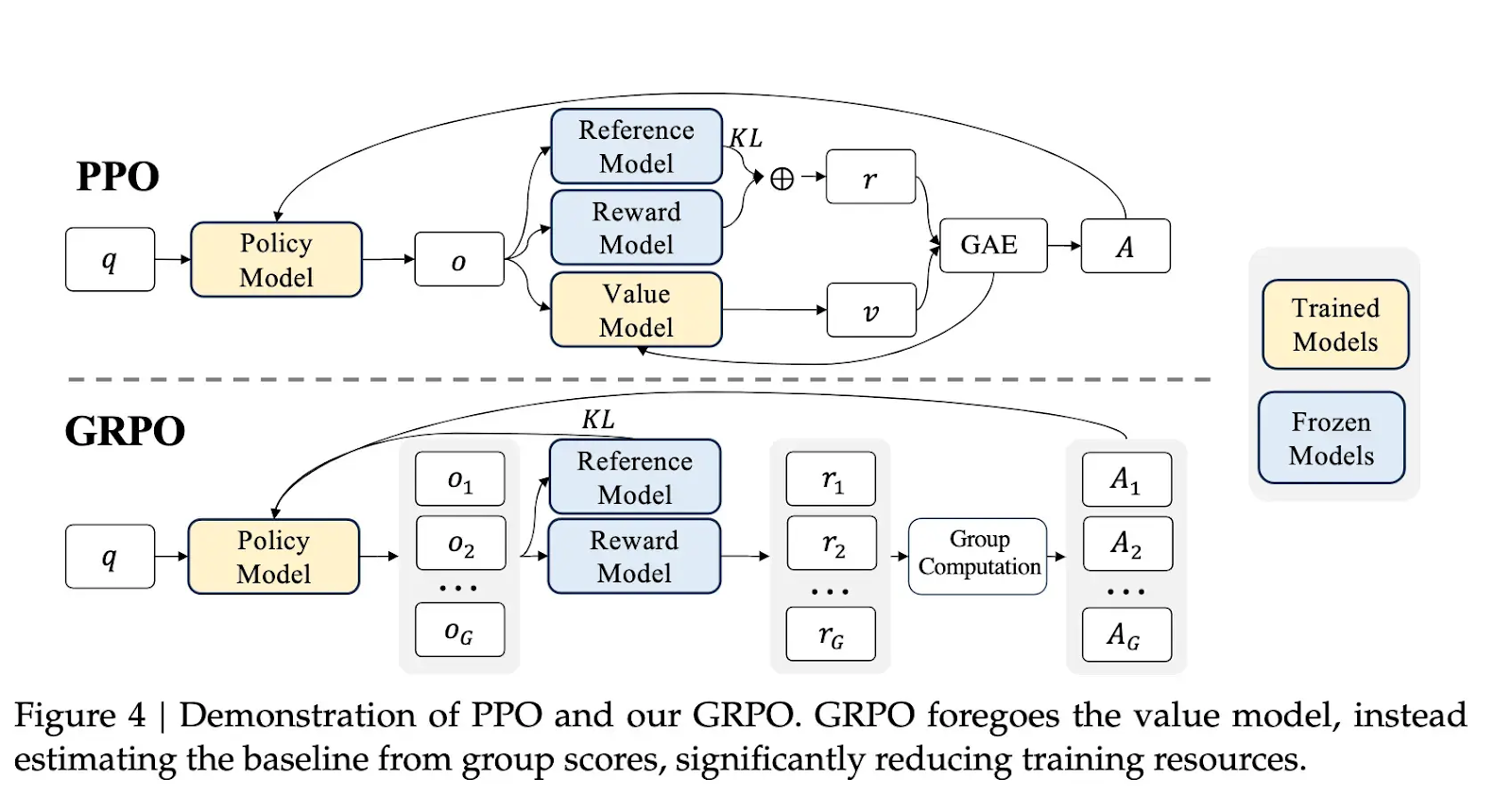
GRPO also uses a 'clipping' mechanism to avoid overconfident updates and ensure a more stable learning process.
GRPO optimises a policy by giving more weight to actions that result in a good reward and less weight to those that have a bad reward. It calculates an "advantage term" which helps evaluate how good each token is in a specific context.
Like DPO, GRPO is an off-policy algorithm that can use previously sampled data to train the model. This is more efficient, as the model doesn't need to generate new outputs at every iteration.
Reward hacking
Reward hacking occurs when a model finds a way to exploit the reward system to get a high score without actually performing the task well. This means that the model focuses on the reward itself, rather than the actual goal.
For example, if a language model is trained to be polite and receives a reward for using the phrase "thank you", it might learn to simply generate the words "thank you" repeatedly, without producing any meaningful or useful content. This is because the model has found a shortcut to achieve a high reward score by gaming the system rather than truly understanding and addressing the task. The model is optimising for the reward, rather than the intended behaviour
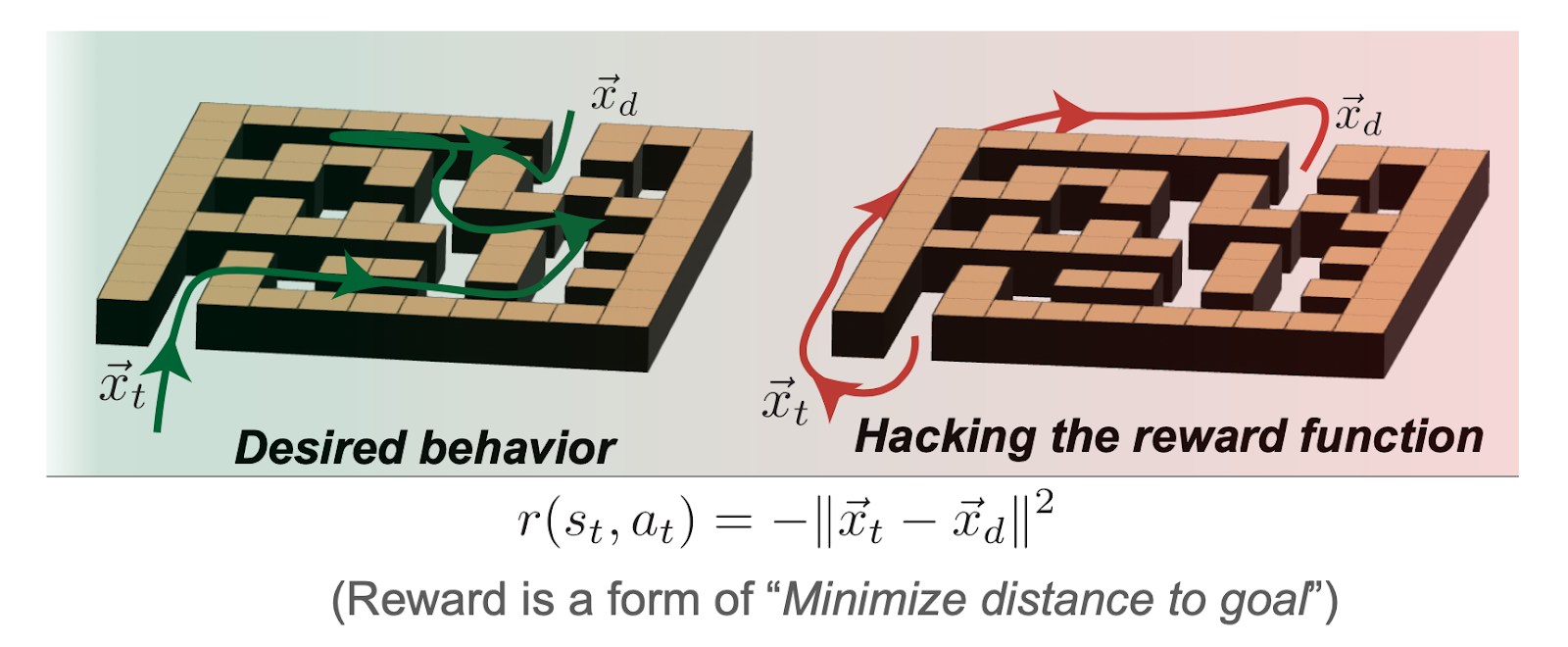
Chain-of-Thought (CoT)
Chain-of-Thought (CoT) is a method that helps Large Language Models (LLMs) solve complex problems by breaking them down into a series of smaller, more manageable steps. It's like showing your working when solving a maths problem, rather than just giving the answer - like how it’s required for all math exams!
The Process
Instead of attempting to solve the whole problem at once, the LLM generates a series of intermediate reasoning steps, leading to the final answer. The LLM generates these steps by predicting the next most probable token, based on the input (the problem) and the tokens generated so far. Thus, the model's thought process is made visible.
By breaking down a problem, the model can better handle complex reasoning, allocating more "thinking time" and improving accuracy.
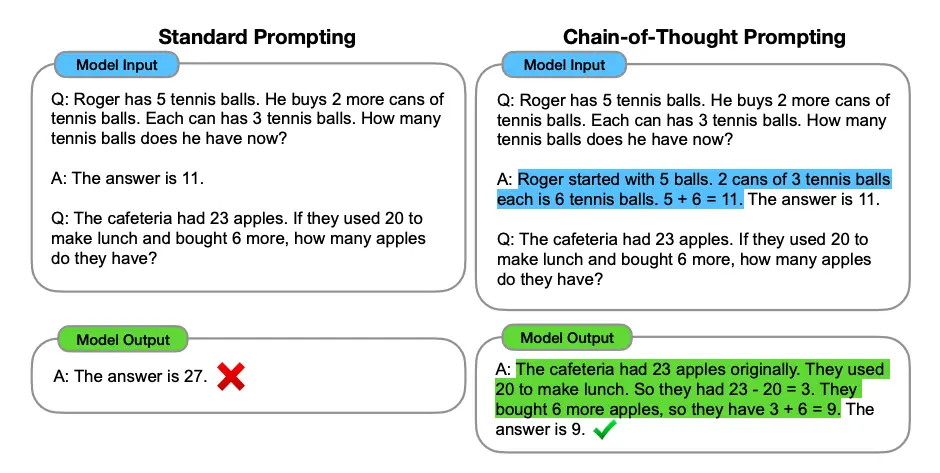
Through CoT, the model's thought process is made visible
CoT improves reasoning by making the logic behind the answer more transparent and allowing the language model to take more steps to reach an answer. The model can learn, through the reward system, that generating longer responses (longer CoTs) can help it get more reward.
I mean, it’s common sense - the more time you are given to think of an answer, the better your answer will be. It’s really as simple as that even in the case of LLMs.
Distillation
Distillation is a technique that allows a smaller "student" model to learn from a larger, more complex "teacher" model. It is exactly like a student learning from a professor, where the student benefits from the professor's knowledge and experience, guided by examples and strategies. This method allows smaller models to learn complex patterns using less resources.
How It Works
A large, pre-trained "teacher" model generates outputs and, more importantly, the probability distributions associated with these outputs.
A smaller "student" model is then trained on these outputs and their probability distributions. The student learns not only what the correct answer is but also the reasoning patterns and likelihoods of different options the teacher used to arrive at the answer.
This means that the student model learns more than just the output, but also the reasoning patterns and strategies used by the larger model.
This is like actually learning the steps to solve a math problem, rather than just memorising the final answer (which would neither be very useful nor practical).
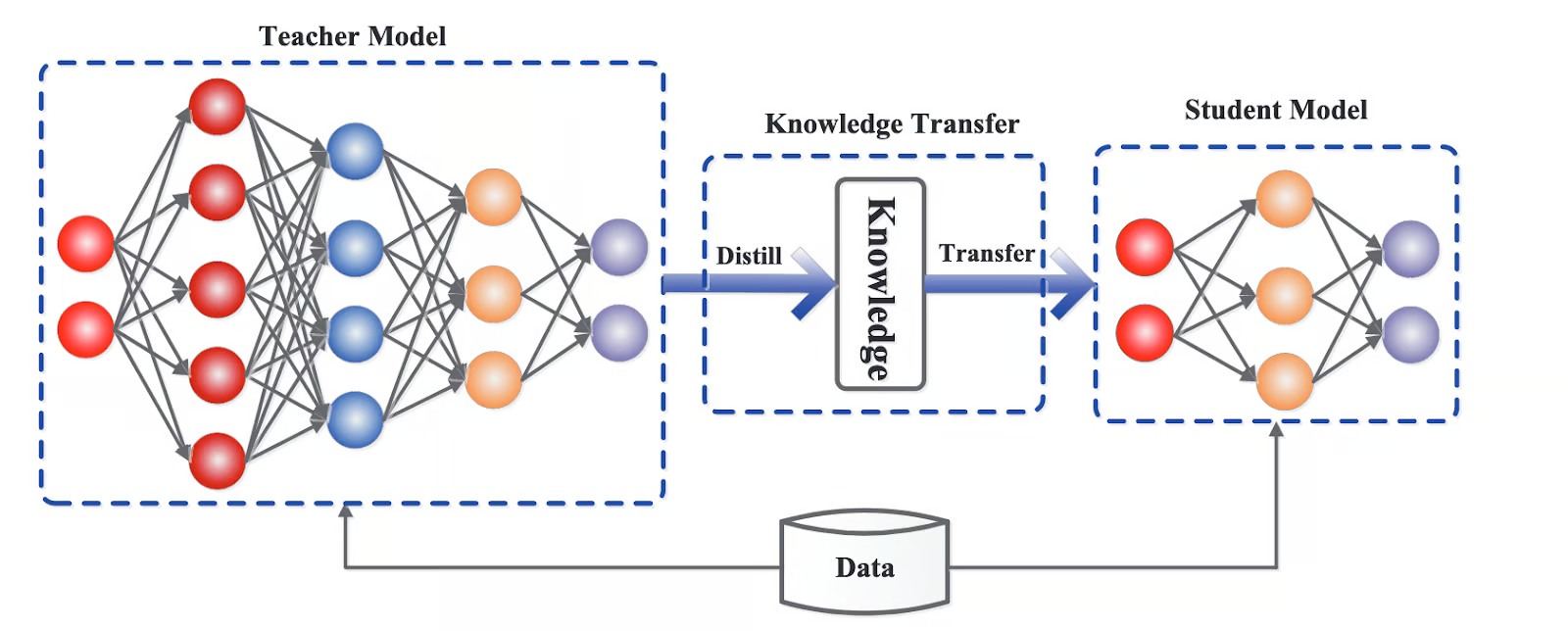
A larger “teacher” model’s knowledge is distilled to the smaller “student” model
The benefits
Smaller, more efficient models which can be deployed on devices with limited resources.
Faster training compared to training from scratch, saving time and resources.
Improved performance as the smaller model mimics the reasoning patterns of the large model.
The ability to learn complex patterns without needing the same level of computational resources.
II. DeepSeek-R1: A Section-by-Section Breakdown
Introduction
DeepSeek-R1 marks a significant step forward in the evolution of Large Language Models (LLMs), with a particular focus on improving their reasoning skills using reinforcement learning (RL). The DeepSeek-R1 project introduces two main models:
DeepSeek-R1-Zero, a model trained purely through RL, without any prior supervised fine-tuning (SFT). This is notable because most models typically use SFT before RL to improve the quality of the training.
DeepSeek-R1, a model that uses a more complex multi-stage training approach that includes a "cold start" using high quality data, as well as additional RL and SFT stages.
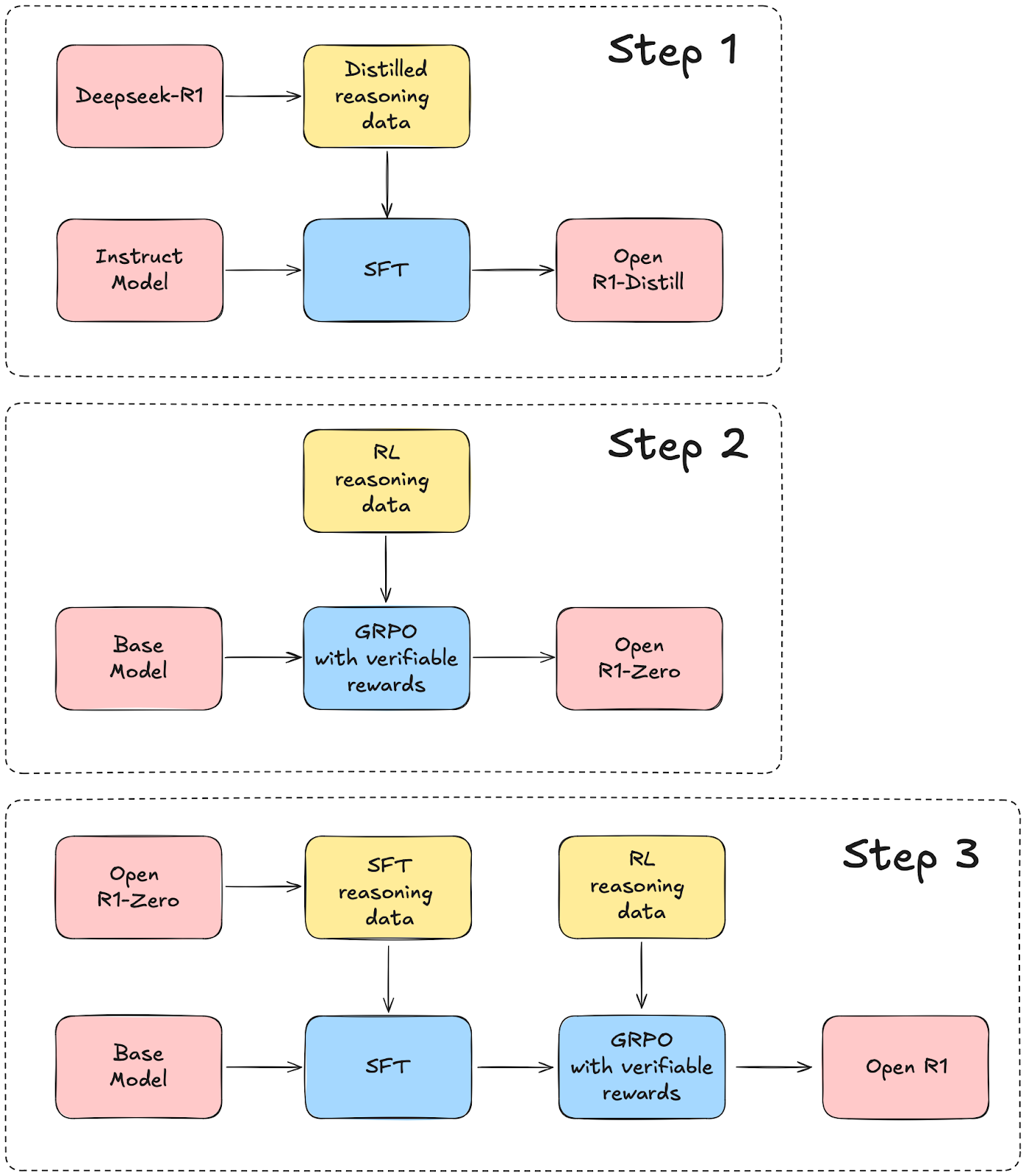
HuggingFace staff are reproducing the full DeepSeek R1 data and training pipeline
The DeepSeek-R1 project has achieved several key milestones:
It has shown that strong reasoning capabilities can be achieved through pure RL, without relying on any initial SFT. DeepSeek-R1-Zero demonstrated the emergence of self-verification, reflection, and the generation of extended "chains of thought" (CoT) during training. Through RL training, DeepSeek-R1-Zero's performance on the AIME 2024 benchmark increased dramatically from 15.6% to 71.0%.
It has developed a multi-stage training approach for DeepSeek-R1 that addresses some of the limitations of DeepSeek-R1-Zero, such as poor readability and language mixing.
It has attained state-of-the-art performance on a variety of reasoning tasks, with DeepSeek-R1 performing at a similar level to OpenAI-o1-1217 on benchmarks like AIME 2024 (79.8% pass@1) and MATH-500 (97.3% pass@1). DeepSeek-R1 also showed expert-level performance on code competition tasks, achieving an Elo rating of 2029 on Codeforces, which is better than 96.3% of human competitors.
It has successfully distilled the reasoning skills of DeepSeek-R1 into smaller, more efficient models. These distilled models have shown impressive performance compared to other open-source models and even some larger models trained from scratch.
The following sections will dive deeper into the methodologies used to develop these models. This will include details of:
The specific algorithms and techniques used such as the Group Relative Policy Optimisation (GRPO) algorithm used in the RL process.
The rule-based reward systems employed to train the models.
The multi-stage training processes for both DeepSeek-R1-Zero and DeepSeek-R1, as well as the distillation technique used to transfer knowledge to smaller models.
The experimental results and the key insights gained from the DeepSeek-R1 project.
Since we have already explored the core concepts discussed in the paper above, you’ll be able to grasp the training methodology sufficiently well.
Without further ado, let’s dive in and see what all the hype is about.
DeepSeek-R1-Zero: Pure Reinforcement Learning
Training Without a Safety Net
DeepSeek-R1-Zero is unique because it was trained using pure reinforcement learning (RL), without any initial supervised fine-tuning (SFT). This is unusual because many language models use SFT before RL. SFT is like giving a model a lot of examples of the type of output you want it to generate, which helps it learn the basic patterns before using RL. DeepSeek-R1-Zero, however, was thrown straight into the RL deep end. This was done to see if the model could develop reasoning skills purely through incentives (rewards) without any prior guidance.
"We directly apply RL to the base model without relying on supervised fine-tuning (SFT) as a preliminary step."
- DeepSeek-R1 Paper
The GRPO Algorithm: Learning by Trial and Error (But Efficiently)
The core of DeepSeek-R1-Zero's training is the Group Relative Policy Optimisation (GRPO) algorithm, a specific type of RL algorithm. Think of RL as a framework where a model (the "agent") takes actions in an environment to maximise a reward. In the case of a language model, the environment is the task it is given (e.g., a math problem), the actions are the choice of the next word (or "token") to generate, and the reward is based on how well it solved the task.
Rule-Based Rewards: Clear Incentives for the Model
Instead of using a trained neural network to judge the model's responses, as in traditional RL for LLMs, DeepSeek-R1-Zero uses a rule-based reward system. This means the reward is calculated based on simple, verifiable rules. There are two main types of rewards:
Accuracy Rewards: These are based on whether the answer is correct. For example, in math problems, the model is rewarded if it gives the right answer in the expected format. For coding problems, the code is run, and the model is rewarded if the code compiles and gives the correct output.
Format Rewards: The model is also rewarded for following the required format, such as putting the thought process in the designated tags.
Why use a rule-based system?
Avoids "Reward Hacking": Neural network reward models can be susceptible to "reward hacking", where the model finds loopholes to get a high reward without actually solving the problem well. Rule-based systems are less vulnerable to this.
Saves Computational Resources: Training a separate neural network reward model is expensive and time-consuming. The rule-based system avoids this overhead and simplifies the training process.
Simple Training Template
During training, DeepSeek-R1-Zero was instructed to put its reasoning process between <think> and </think> tags, and the final answer between <answer> and </answer> tags. This is the only real constraint put on the model, so the way the model develops its reasoning is a natural, self-evolving process.

Emergent Behaviours: The Model Learns to Think
Now let's explore the fascinating behaviours that emerged as DeepSeek-R1-Zero trained, and the performance it achieved.
During its pure RL training, DeepSeek-R1-Zero started exhibiting some interesting and unexpected behaviours:
Self-verification and Reflection: The model began to show signs of self-checking and reflection, going back to re-evaluate its previous steps, showing an understanding of its own thought process. This wasn't something that was programmed into the model, but something it learned through the RL process.
Long Chains of Thought (CoT): The model learned to generate long chains of thought as it trained. This means that for complex problems, the model started generating longer, more detailed reasoning steps to arrive at an answer. This was a "self-evolution" process where the model autonomously learned to allocate more "thinking time" to solve problems, extending its responses and going into more depth. The more it trained, the longer the responses became. The model learned that generating more detailed responses was the best way to gain a reward, because the reward system was based on whether the output was correct.
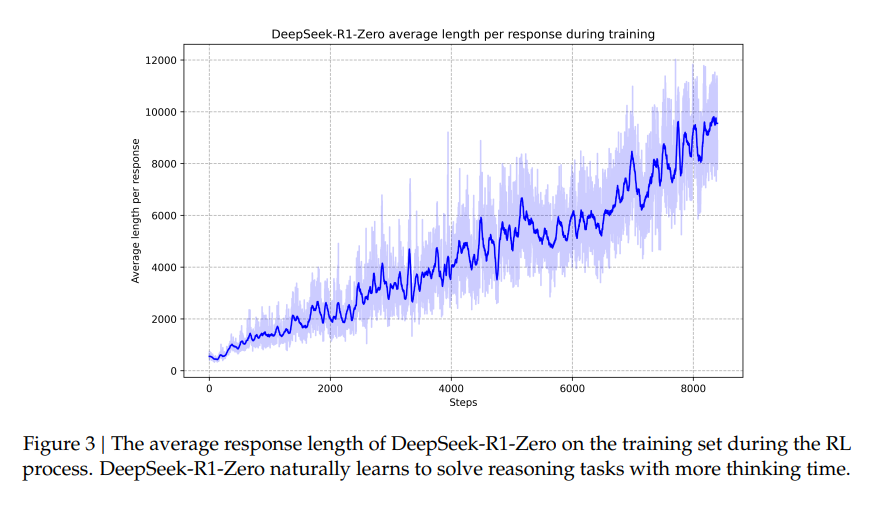
The "Aha Moment": One particularly interesting thing that the researchers observed during the training was an "aha moment". This is where the model learned to re-evaluate its initial approach mid-problem. For example, the model might start solving a math problem in one way, then stop itself, rethink, and correct its approach. This wasn't a planned behaviour, but an emergent outcome of the training process, illustrating the power and beauty of RL.

Performance Results: Competing with Top Models
DeepSeek-R1-Zero demonstrated impressive performance on several benchmarks:
AIME Benchmark: On the AIME 2024 benchmark, the average pass@1 score of DeepSeek-R1-Zero increased from 15.6% to a very impressive 71.0%. This shows how effectively the model's performance improved as it went through the RL training process.
Comparison with OpenAI-o1-0912: The model’s final performance was comparable to OpenAI’s o1-0912 model on a range of reasoning benchmarks, which is a major achievement. DeepSeek-R1-Zero achieved a 71.0% pass@1 score on AIME, compared to 74.4% for OpenAI-o1-0912.
Majority Voting: By using majority voting, the model's performance was improved even further. For example, the pass@1 score on the AIME benchmark increased from 71.0% to 86.7%. Majority voting involves generating multiple responses to a problem and then choosing the most common one. The fact that this process can increase performance is a sign that the model is generating good reasoning for a large number of attempts, even if those attempts are not always individually correct.
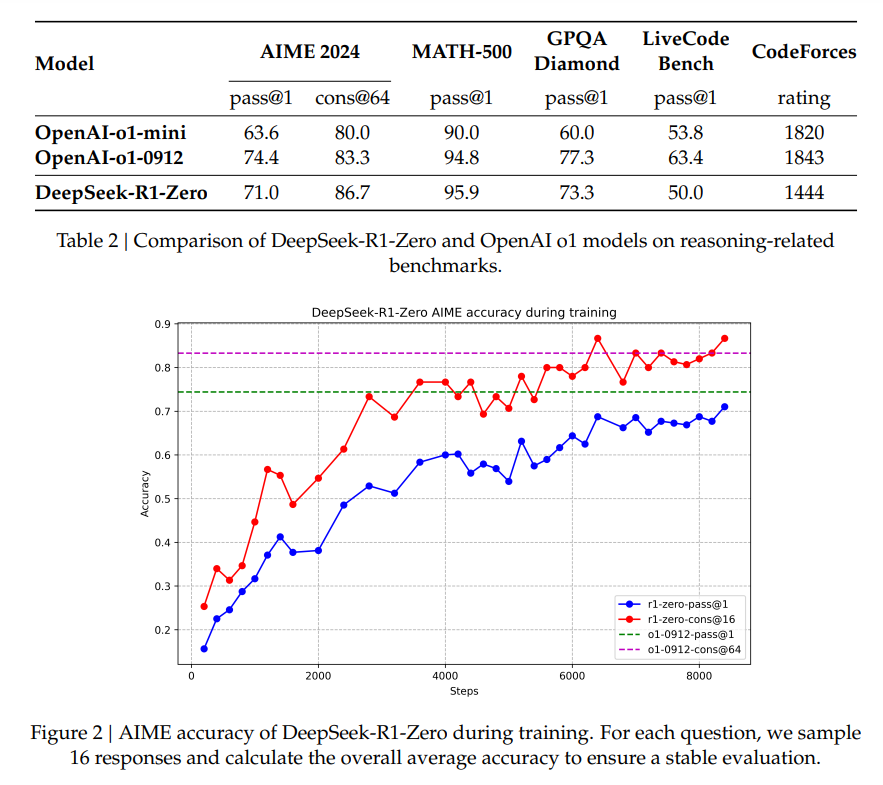
Limitations of DeepSeek-R1-Zero: The Need for Refinement
While DeepSeek-R1-Zero showed strong reasoning capabilities, it also had some limitations:
Poor Readability: The model's output was not always easy to read. The text often lacked formatting and could be difficult to follow.
Language Mixing: The model sometimes mixed different languages within its responses, which made them hard to understand.
These limitations of DeepSeek-R1-Zero paved the way for DeepSeek-R1, which incorporated additional stages of training to address these issues.
DeepSeek-R1: A Multi-Stage Approach to Refinement
DeepSeek-R1 was created to overcome the issues of poor readability and language mixing that were seen in DeepSeek-R1-Zero. It uses a more complex, multi-stage training approach, building on the foundation laid by R1-Zero, but adding more steps to make the model more user-friendly and capable.
"Cold Start": A Guiding Hand Before Reinforcement Learning
Unlike DeepSeek-R1-Zero, which started with pure RL from the base model, DeepSeek-R1 uses a "cold start" approach. This involves giving the model some high-quality data for initial fine-tuning before the RL training begins. This "cold start" data is intended to provide a more stable starting point for the RL phase, and to improve readability of the outputs.
Different methods were used to generate this data:
Few-shot prompting: Using examples with long chains of thought.
Direct prompting: Asking the model to generate detailed answers with reflection and verification.
Refining R1-Zero outputs: Gathering DeepSeek-R1-Zero outputs and refining them into a more readable format.
Human annotation: Post-processing by human annotators to improve the quality of the collected data.
Benefits of Cold Start Data
The inclusion of the cold start data offers several benefits:
Improved Readability: DeepSeek-R1-Zero's output was often difficult to read, with mixed languages and a lack of formatting. The cold start data helps by including a readable pattern with a summary at the end of each response, also filtering out responses that are not reader-friendly. The format used is: |special_token|<reasoning_process>|special_token|<summary>. The reasoning process is the Chain of Thought (CoT) for the query, and the summary is used to summarise the reasoning results.
Performance Boost: The models also demonstrated better performance against DeepSeek-R1-Zero as a result of the carefully designed patterns for cold-start data, which incorporate human expectations of how the models should act. It is believed this is because the iterative training approach is better for the model.
Reasoning-Oriented Reinforcement Learning
After the cold start fine-tuning, DeepSeek-R1 undergoes a large-scale, reasoning-oriented reinforcement learning process, similar to the one used for DeepSeek-R1-Zero. This phase focuses on improving the model's reasoning capabilities in areas like coding, math, science and logical reasoning.
Language Consistency Reward: During this stage, a language consistency reward is introduced to mitigate the problem of language mixing. This reward is based on the proportion of target language words in the Chain of Thought (CoT), ensuring the model sticks to the correct language. Although this can slightly degrade performance, it improves the readability of the output. The final reward is a combination of the accuracy of reasoning tasks and this language consistency reward.
Rejection Sampling and Supervised Fine-Tuning (SFT)
Once the reasoning-oriented RL converges, the next stage involves a combination of rejection sampling and supervised fine-tuning (SFT).
Expanded Dataset: Unlike the initial cold-start data, which was mainly focused on reasoning, this stage introduces data from other domains such as writing, role-playing, and other general-purpose tasks, thereby enhancing the model’s general capabilities.
Rejection sampling: This method filters generated responses, keeping only the correct ones. In the previous stage, only data that could be evaluated using rule based rewards was used, but this stage expands the dataset to include data with a generative reward model.
DeepSeek-V3 Data: For non-reasoning tasks, the training pipeline reuses portions of the SFT dataset of DeepSeek-V3 and also calls DeepSeek-V3 to generate a chain of thought before answering the question. In simpler cases, like "hello," a CoT is not generated. This stage generates about 600,000 reasoning related samples, and 200,000 non-reasoning related training samples. The DeepSeek-V3-Base model is then fine-tuned for two epochs using the 800,000 sample data set.
Final Reinforcement Learning for All Scenarios
The final stage is another round of reinforcement learning, which aims to further align the model to human preferences.
Helpfulness and Harmlessness: This stage focuses on improving the model’s helpfulness and harmlessness. For reasoning data, the model follows the DeepSeek-R1-Zero methodology, using rule-based rewards. For general data, reward models are used to capture human preferences in complex scenarios.
Helpfulness is evaluated solely based on the final summary, focusing on the utility and relevance of the response to the user.
Harmlessness is evaluated based on the entire response, including both the reasoning process and the summary, to mitigate any potentially harmful or biased content.
Distillation: Transferring Reasoning to Smaller Models
The DeepSeek-R1 research team used distillation to transfer the advanced reasoning capabilities of the larger DeepSeek-R1 model to smaller, more efficient models. This is important because large language models can be computationally expensive and impractical for many applications. As we have already explored previously, distillation allows for the creation of models that are easier to use while still retaining a high level of performance
"Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community... The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks."
- DeepSeek-R1 Paper
Impressive Performance of Distilled Models
The research showed that this distillation process led to smaller models achieving impressive performance, often outperforming other open-source models and even larger models that were trained from scratch. It's particularly important that the distilled models were trained using supervised fine-tuning (SFT) only, without any additional reinforcement learning (RL). This shows that distillation is an effective method for knowledge transfer
Let's compare the performance of the distilled models with other models. Here are some results from the research paper:
The distilled models, such as DeepSeek-R1-Distill-Qwen-7B, 14B and 32B, showed significantly improved performance in reasoning tasks compared to models such as GPT-4o-0513 and Claude-3.5-Sonnet-1022.
The DeepSeek-R1-Distill-Qwen-14B model outperformed the open-source QwQ-32B-Preview model across the board.
The DeepSeek-R1-Distill-Qwen-32B and 70B models surpassed OpenAI-o1-mini on most benchmarks.
These performance gains were achieved with SFT only and without the use of RL.
The research found that the distillation strategy was both more economical and effective compared to directly applying large-scale RL to the smaller base models.
Discussion: Key Findings and Insights
Finally, let's explore the key findings and insights from the DeepSeek-R1 research, focusing on the conclusions drawn from DeepSeek-R1’s training, and the lessons learned from both successes and unsuccessful attempts.
Reinforcement Learning and Self-Evolution
A key finding of the DeepSeek-R1 research is that reinforcement learning (RL) can be a powerful way to improve reasoning in large language models (LLMs), even without supervised fine-tuning (SFT) as a preliminary step. The DeepSeek-R1-Zero model demonstrated this by being trained purely with RL, using a rule based reward system and the GRPO algorithm. This pure RL approach allowed researchers to observe the model's self-evolution, which is a fascinating process.
Self-Evolution: During the RL training, DeepSeek-R1-Zero was seen to develop its own strategies for problem-solving, such as self-verification, reflection, and generating longer "chains of thought" (CoTs). The model spontaneously learned to allocate more "thinking time" (longer CoTs) to solve complex problems. In essence, the model was learning how to think more effectively simply through the incentives of the reward system.
Intriguing Behaviours: The "aha moment" where the model reevaluated its initial approach and corrected itself is a striking example of its self-directed learning. This shows that with the right incentives, LLMs can develop reasoning skills autonomously.
"The self-evolution process of DeepSeek-R1-Zero is a fascinating demonstration of how RL can drive a model to improve its reasoning capabilities autonomously."
- DeepSeek-R1 Paper
Distillation vs. Large-Scale RL for Smaller Models
The research also compared the effectiveness of distillation with large-scale RL for smaller models. The results showed that distillation was more effective than directly training smaller models with RL.
While a smaller model (Qwen-32B-Base) trained with large-scale RL (DeepSeek-R1-Zero-Qwen-32B) did achieve results comparable to another similarly sized model, QwQ-32B-Preview, the distilled model (DeepSeek-R1-Distill-Qwen-32B), which was trained using SFT and the knowledge of the larger DeepSeek-R1 model, significantly outperformed it. This demonstrates that transferring knowledge from a larger model is a more efficient approach than training a smaller model from scratch with RL.
“Distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation."
- DeepSeek-R1 Paper
DeepSeek-R1-Zero vs. DeepSeek-R1
While DeepSeek-R1-Zero showed strong reasoning capabilities, it had some limitations such as poor readability and language mixing. To address these, the researchers developed DeepSeek-R1. The key differences are:
DeepSeek-R1-Zero: Trained purely through RL without any prior SFT, demonstrating self-evolution and strong reasoning capabilities but with issues in readability and language mixing.
DeepSeek-R1: Utilized a multi-stage training process including a "cold start" phase, using SFT and RL, to improve readability, formatting, and overall performance. The process included using high-quality data for the initial fine-tuning, which helped to provide a more stable foundation for the subsequent RL training, while also encouraging a more human-readable output format.
Unsuccessful Attempts: PRM and MCTS
The researchers also explored and then abandoned other approaches, providing insights into what didn’t work as well:
Process Reward Models (PRM): While PRM seemed like a good approach, it proved difficult to define fine-grained steps for general reasoning. The researchers found it challenging to determine the correctness of each step, and the use of model-based PRM led to reward hacking. They also found that manual annotation was difficult to scale. Therefore, PRM did not perform well in their experiments and was deemed less effective than other approaches.
Monte Carlo Tree Search (MCTS): MCTS, inspired by AlphaGo, was used to improve test-time compute scalability by breaking answers into smaller parts. Although MCTS can improve performance during inference when paired with a pre-trained value model, iteratively boosting model performance through self-search proved to be a significant challenge. Ultimately, the RL-based approaches performed better.
Rule-Based Reward Systems
The researchers chose to use a rule-based reward system, instead of a neural network based model as is more commonly used in RLHF (Reinforcement Learning from Human Feedback).
Benefits of Rule-Based Rewards: This was especially useful in the DeepSeek-R1-Zero experiments, which used a reward system that assigned rewards based on verifiable task outcomes. For example, for LeetCode problems, the model was rewarded based on whether the generated code compiled and produced the correct results. This method avoids the potential for reward hacking and eliminates the need for additional training resources to train a separate neural network reward model.
Robust and Easier to Implement: Rule based reward systems are more robust and easier to implement, because they are based on explicit rules that can be easily verified, unlike neural network based reward models which are difficult to debug, as they require separate data to train. This makes the training process simpler and more efficient.
Cost-Effective Distillation and Open Sourcing
Lastly, the research showed that distillation is a cost-effective way to train smaller models with strong reasoning abilities, and is more efficient than directly training these smaller models using large scale RL. By open-sourcing the DeepSeek-R1 models, the researchers have enabled the wider AI research community to further develop and build upon their work. The open-sourcing also allows the community to distill their own models with the help of DeepSeek-R1 models.
The End
Okay, we are finally through the comprehensive and complete breakdown of the DeepSeek-R1 research paper. I hope bh this point you have a solid understanding of the core concepts that influenced the training of DeepSeek-R1 and can appreciate its novelty and potential.
I, for one, am incredibly excited about this huge step forward in the generative AI field. With such a state-of-the-art LLM being open-sourced, and having been trained on remarkably low compute, AI seems more accessible than ever and now the potential for further advancements in the field has increased significantly. I’m counting down time until the next great open-source innovation that leaves OpenAI in the dust!
Acknowledgements
I’d like to show my appreciation for this absolutely brilliant video on the DeepSeek-R1 paper by Umar Jamil. It really helped me understand the paper and all its concepts.